
Genom Yapısı ve Fonksiyonel Anotasyon: Yöntemler ve Veri Tabanları
- Ceyda Güven

- 19 Eyl 2025
- 6 dakikada okunur
Genom, organizmalarda kalıtımın temelini oluşturan yapıdır. Genomik bilgi, organizma hakkında sunulan bir kütüphane gibidir. Hücrelerin büyüme, gelişme, metabolizma gibi temel biyolojik işlevlerini yönlendirmesinin yanı sıra kodlanmayan DNA bölgeleri, regülatör bölgeleri ve tekrarlayan dizileri de içermektedir. Genom tanımı yalnızca DNA ile sınırlı değildir. Doğada bazı canlılarda genetik materyal RNA içerisinde bulunur. RNA virüsleri buna örnek verilebilir. Genomik araştırmalar yaşam bilimlerinin farklı alanlarında oldukça önemli bilgiler sağlamaktadır. Evrimsel biyoloji sık araştırılan, türlerin kökeni ve akrabalık ilişkilerinin açığa çıkarılması gibi konuları kapsayan bir araştırma alanıdır. Genom dizilerinin benzerlik, farklılıklarının gözlenmesine dayanır. Genom analizleri tıpta hastalık araştırmalarında da büyük önem taşımaktadır. Genetik hastalıklarının nedenlerinin çözümlenmesi, kanser gibi kompleks hastalıkların moleküler temellerine ışık tutması, kişiselleştirilmiş tıbbın geliştirilmesi gibi birçok alanda genom analizleri yer almaktadır.
Dizileme teknolojileri genomik analizlerin gerçekleştirilmesine olanak sağlar ve sürekli geliştirilmektedir. DNA dizileme kavramının ortaya atılmasını sağlayan Sanger, 1977 yılında Sanger dizileme adı verilen bir yöntem geliştirmiştir. Genom biliminin temeli bu şekilde atılmış olsa da Sanger dizileme yöntemi sınırlı ölçekteydi. Bu nedenle Yeni nesil dizileme (NExt-Generation Sequencing) teknolojisi ortaya çıkmıştır. Bu teknolojinin ortaya çıkışı milyonlarca DNA parçasının aynı anda yüksek hızda dizilenmesine imkan tanımıştır. 3. nesil dizileme teknolojileri ise tek molekül üzerinden uzun okuma elde etme yeteneği ile karmaşık bölgelerin çözülmesine katkı sağlamıştır (1,2). DNA’nın kodlayan bölgeleri olan genler, protein veya fonksiyonel RNA’ların sentezinden sorumludur. Ekzon ve intronlardan meydana gelen genler translasyon sürecinde aminoasit dizilerine çevrilerek işlevlerini yerine getirir. İnsan genomunun yalnızca %2’lik kısmının kodlama yaptığı bilinir. Kalan %98’lik kısım kodlama yapmamaktadır. Kodlamayan kısımların biyolojik rolleri oldukça kritiktir. Gen düzenlemeleri, alternatif splicing mekanizmaları, intergenik bölgeler içerir. Regülatör bölgeler olarak adlandırılan yapılar promoterları, enhancer ve silencerları içerir. Bu bölgeler gen ekspresyonunun kontrolünde anahtar rol oynar. Genomda bulunan bu düzenleyici diziler, hücrelerin gen ekspresyon profillerini oluşturmaktadır (3).
Fonksiyonel Anotasyon Nedir?
Fonksiyonel anotasyon, genom dizilerinden elde edilen potansiyel genlerin biyokimyasal işlevlerini ve biyolojik rollerini tahmin etme yani onlara biyolojik bilgi ekleme sürecidir. Yapısal anotasyon, genlerin yerlerini ve ekzon-intron düzenini belirlemekle sınırlıyken; fonksiyonel anotasyon, bu genlerden türeyen proteinlerin hangi süreçlerde görev aldığını açıklamaya çalışır. Biyoinformatik analizlerde genlerin hangi süreçlere nasıl katkıda bulunduğu, hangi yolaklara veya ağlara dahil olduğu sorularını cevaplandırabilmek için fonksiyonel anotasyon temel adımdır (4).
Fonksiyonel Anotasyon Yaklaşımları
Genlere biyolojik işlevler atamak için bilinen genlerle olan benzerliğe göre tahmin algoritmaları kullanılabilir. Ayrıca dizilerin mevcut veri tabanlarıyla homoloji aramalarıyla da işlev atamaları yapılabilir. Başlangıçta dizi hizalama araçları ile bilinen genlerle benzerlikler bulunur. Dizileri karşılaştıran BLAST (Basic Local Alignment Search Tool) gibi bazı araçlar mevcuttur. Ayrıca Gen Ontology (GO) analizi ile genlerin ne yaptığını kategorize etmek ve tanımlamak mümkündür. Yalnızca protein kodlayan genler değil mikroRNA, ribozomal RNA gibi kodlamayan bölgeler de bu işlem ile gerçekleştirilebilir. Promoter, enhancer, transkripsiyon faktörü bağlanma bölgesi gibi kontrol bölgeleri de genlerin hücre işleyişindeki rolünde bilgi sahibi olmamıza yardımcı olmaktadır. Fonksiyonel anotasyonun temel adımlarından biri protein kodlamayan bölgelerin tanımlanmasıdır. Kodlama yapmayan diziler ayrıştırılır. Ardından kodlama yapan bölgelerin gen sınırları belirlenmektedir. Genin çevresinde bulunan bazı düzenleyici bölgeler bu aşamada rehber işlevi görmektedir. Genlerin belirlenmesinin ardından tanımlanan genlere fonksiyonel etiketler atanır (5).
Dizi Yapısına Dayalı Yöntemler
Fonksiyonel anotasyonda kullanılan yöntemler ve araçlar oldukça fazladır. Farklı veri tabanları ve araçları kullanarak anotasyon adımını tamamlamak mümkündür. Dizi benzerliği tabanlı yöntemlerde BLAST ve FASTA gibi araçlar kullanılır. BLAST en yaygın kullanılan araç olmakla beraber, analiz edilecek gen veya protein dizilerinin bilinen dizilerle hizalanmasını ve benzerlik yüzdeleri üzerinden işlev tahmini yapılmasını sağlar. FASTA da aynı şekilde dizilerin hizalanmasına dayanan başka bir algoritmadır (6).
Evrimsel Yaklaşımlar
Evrimsel yaklaşımlarda ise ilişkili genlerin incelenmesi fonksiyon tahminlerinde güçlü bir araçtır. Ortolog-paralog analizleri işlevi belirleme sürecinde yol gösterici olabilir. COG (Clusters of Orthologous Groups) veya ökaryotlar için özelleştirilmiş KOG (EuKaryotic Orthologous Groups) gibi araçlarla proteinleri evrimsel akrabalarına göre gruplandırarak fonksiyonel sınıflandırma yapılabilir. COG, bakteri ve arke genlerinin kapsamlı işlevsel açıklamasının; evrimsel kökenleri yansıtan dizi benzerliğine göre belirlenmesini sağlayan bir araçtır (6).
Ontoloji tabanlı analizler
Gene Ontology (GO), genlerin ve proteinlerin biyolojik işlevlerini standart bir dil ve hiyerarşik bir yapı içinde tanımlamayı amaçlayan uluslararası bir biyoinformatik projesidir. Fonksiyonel anotasyon sürecinde yaygın olarak kullanılan GO sistemi, genlerin biyolojik rollerini üç ana kategori altında sınıflandırır. Bunlar; biyolojik süreç (Biological Process - BP), moleküler işlev (Molecular Function - MF) ve hücresel bileşen (Cellular Component – CC) terimleridir. Biyolojik süreç terimi gen veya gen ürününden gelen biyolojik amacı ifade etmektedir. Düzenli moleküler yapıların bir araya gelerek fiziksel veya kimyasal dönüşüm ile süreç içerisinde başka yapılara dönüşmesi ile de ifade edilebilir. Hücre büyümesi, sinyal iletimi gibi üst düzey biyolojik süreçlerin yanında alt düzey olarak adlandırılan daha spesifik olan translasyon ve primidin metabolizması gibi süreçleri de içerir. Moleküler işlev terimi adından da anlaşılabileceği üzere bir genin veya gen kompleksinin işlevinin en olduğunu veya olabileceğini tanımlar. Bunun yanında, bir gen ürününün belirli ligandlara veya yapılara bağlanma aktivitesini, ayrıca sahip olabileceği biyokimyasal aktivite potansiyelini de açıklar. Örneğin “enzim”, “taşıyıcı”, “reseptör ligandı” gibi tanımlar bu kategorinin içerisinde yer alır. Hücresel bileşen ise bir gen ürününün hücre içinde aktif olduğu yeri ifade eder. Hücresel bileşenler ribozom, proteazom, golgi aygıtı ve çekirdek membranı gibi terimleri kapsar. Burada yer alan terimler ökaryotik hücre yapısını kapsamaktadır (7).
Yaygın olarak kullanılan bir başka araç olan KEGG, genomik dizileri üst düzey işlevsel verilerle bütünleştiren kapsamlı bir bilgi kaynağıdır. GENES modülü, tamamen dizilenmiş tüm organizmaların yanı sıra belli başlı kısmi genomların güncel gen kataloglarını içerir. PATHWAY bölümü ise metabolizma, membran taşınması, hücre döngüsü ve sinyal iletimi gibi temel biyolojik süreçleri grafiksel olarak sunar. Bu grafikler, gen işlevlerini tahmin etmeyi kolaylaştıran korunmuş alt yolak motiflerini de ortaya koyan ortolog grup tablolarıyla desteklenir. Üçüncü ana bileşen olan LIGAND veri tabanı, kimyasal bileşikler, enzimler ve bunlar arasındaki reaksiyon ağları hakkında ayrıntılı bilgiler sağlar. KEGG, Java tabanlı etkileşimli araçlarla genom haritalarının taranmasına, haritalar arası karşılaştırma ve ifade profillerinin düzenlenmesine imkân tanıdığı gibi dizi karşılaştırma ve yolak hesaplama algoritmalarını da bünyesinde barındırır. Veri tabanları her gün güncellenir ve araştırmacıların ücretsiz kullanımına açıktır (8).
Veri Tabanı Sorgulama
Genom anotasyonu sürecinde veri tabanları ham (raw) dizilerden anlamlı bilgiye ulaşma sürecinde temel rol oynar. Dizileme teknolojilerinden elde edilen genomlar tek başına anlam ifade etmez ve yorumlanamazlar. Verilerin anlamlı bir bağlamda kullanılabilmesi için veri tabanlarıyla karşılaştırılması gerekir. Ayrıca farklı araştırmacıların ortak bir terminoloji kullanabilmesi için standardizasyon sağlanır. Genom anotasyonu aşamasında kullanılan veri tabanları bilimsel geçerlilik ve tekrarlanabilirlik açısından kritik öneme sahiptir. Temel genom ve transkriptom veri tabanları, anotasyon platformları, protein odaklı veri tabanları; analizin bu aşamasında araştırmacılara destek olur. 1999 yılında başlayan Ensembl genom veri tabanı projesi bugün de en kapsamlı ve sık kullanılan veri tabanlarından biridir. Gen setleri, ortolog ve paralog genlerin anotasyonları, kapsamlı varyasyon ve regulator (düzenleyici) bilgileri olmak üzere büyük ve eksiksiz bir genomik bilgi kaynağı olarak kullanılmaktadır. Kaynağın sunduğu BioMart aracı sayesinde büyük genom veri kümeleri içinde sorgulamalar gerçekleştirilebilir. Ensembl arayüzü Şekil 1.’deki gibi görünmektedir (9).

2002 yılında tanıtılan USCS Genome Browser, genom anotasyonu ve görselleştirilmesinde yaygın olarak kullanılan bir platformdur. Kullanıcılar gen bölgesinde yer alan ekzon-,ntron yapılarını, regülatör bölgeleri, varyasyonları görüntüleyebilirler. Kullanıcılar kendi verilerini yükleyerek varsa referans genomlar ile karşılaştırma yapabilirler. Web sitesinin anasayfası Şekil 2.’deki gibi görünmektedir. “See our new tutorials page!” butonundan kullanım rehberlerine ulaşılabilir (11).

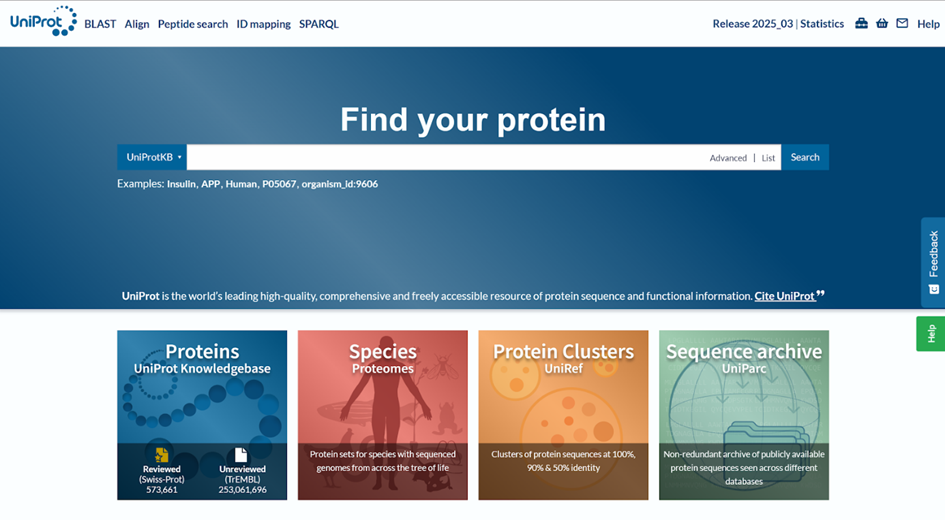
Universal Protein Resource (UniProt) ise protein dizileri ve fonksiyonel analiz için en kapsamlı ve güvenilir veri tabanlarından biridir. 2007 yılında resmi olarak duyurulan bu kaynak, Swiss-Prot, TrEMBL, PIR-PSD veri tabanlarının birleştirilmesiyle oluşturulmuştur. UniProt, proteinlerin dizileri, yapıları, fonksiyonları, hücresel lokalizasyonları ve etkileşimleri hakkında ayrıntılı bilgi verirken, KEGG gibi diğer veri tabanlarıyla da çapraz bağlantılar kurarak araştırmacıların bilgiye erişmesini kolaylaştırır. UniProt arayüzü Şekil 3.’teki gibi görünmektedir (13).
Genom anotasyonu, dizileme teknolojilerinden elde edilen ham verilerin biyolojik anlamlandırılması sürecidir. Bu süreçte kodlayan ve kodlamayan bölgelerin tanımlanması, genlerin işlevlerinin belirlenmesi ve biyolojik ağlara yerleştirilmesi kritik öneme sahiptir. Ensembl, UCSC Genome Browser, UniProt ve KEGG gibi veri tabanları, araştırmacılara genomların fonksiyonel yorumlanmasında kapsamlı destek sunmaktadır.
Sonuç olarak genom anotasyonu, hem temel araştırmalar hem de klinik ve endüstriyel uygulamaların vazgeçilmezidir. Hastalıkların anlaşılmasından yeni tedavi hedeflerinin bulunmasına, biyoteknolojideki ilerlemelerden tarımsal verimliliğe kadar pek çok alanda bilimsel gelişmelerin önünü açmaktadır.
Referanslar
1) Metzker, M. L. (2010). Sequencing technologies — the next generation. Nature Reviews Genetics, 11(1), 31–46. https://doi.org/10.1038/nrg2626
2) Pareek, C. S., Smoczynski, R., & Tretyn, A. (2011). Sequencing technologies and genome sequencing. Journal of Applied Genetics, 52(4), 413–435. https://doi.org/10.1007/s13353-011-0057-x
3) Monti, R., & Ohler, U. (2023). Toward identification of functional sequences and variants in noncoding DNA. Annual Review of Biomedical Data Science, 6(1), 191–210. https://doi.org/10.1146/annurev-biodatasci-122120-110102
4) Aubourg, S., & Rouzé, P. (2001). Genome annotation. Plant Physiology and Biochemistry, 39(3–4), 181–193. https://doi.org/10.1016/S0981-9428(01)01242-6
5) Hashmi, H. (2022). Functional annotation of genomes: A comprehensive review. In S. Singh & R. K. Dwivedi (Eds.), Bioinformatics computing (pp. 84–89).
6) Galperin, M. Y., Vera Alvarez, R., Karamycheva, S., Makarova, K. S., Wolf, Y. I., Landsman, D., & Koonin, E. V. (2025). COG database update 2024. Nucleic acids research, 53(D1), D356–D363. https://doi.org/10.1093/nar/gkae983
7) Ashburner, M. et al. (2000). Gene ontology: tool for the unification of biology. Nature Genetics 25, 25–29. https://doi.org/10.1038/75556
8) Kanehisa, M. & Goto, S. (2000) KEGG: Kyoto Encyclopedia of Genes and Genomes. Nucleic Acids Research 28(1):27–30. https://doi.org/10.1093/nar/28.1.27
9) Flicek, P. et al. (2009) Ensembl's 10th year, Nucleic Acids Research, Volume 38, Issue suppl_1, 1 January 2010, Pages D557–D562, https://doi.org/10.1093/nar/gkp972
11) Kent, W. J., Sugnet, C. W., Furey, T. S., Roskin, K. M., Pringle, T. H., Zahler, A. M., & Haussler, D. (2002). The human genome browser at UCSC. Genome research, 12(6), 996–1006. https://doi.org/10.1101/gr.229102
13) UniProt Consortium. (2007). The Universal Protein Resource (UniProt). Nucleic Acids Research, 35(suppl_1), D193–D197. https://doi.org/10.1093/nar/gkl929



Yorumlar